In the second part of the post, we’ll look at some web UIs that provide a complete set of features, like data visualization, topics administration, etc.
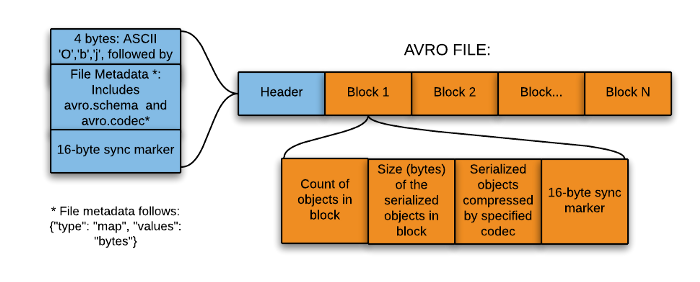
First, we need to pay attention to how we are serializing the data in Kafka, whether it is using vanilla Avro, Json, Confluent Avro, Protobuf, or just binary format.
For example, focusing on Avro, the main difference between Confluent Avro and vanilla Avro is whether it expects the schema id in the Avro payload. In Confluent Avro, a schema id is always needed at the start of the payload.
Useful Links
Apache Kafka CLI commands
Using the Kafka CLI commands, we will be able to list the different topics available on our cluster and consumer the events.
If we work in an environment with docker containers, we can find them inside the container in the bin/ folder.
kafka-topics.sh
This CLI script allows us to list, create, and describe the topics available on our cluster.
create topics
$ bin/kafka-topics.sh --create --topic topicName --bootstrap-server broker:9092
describe topics
$ bin/kafka-topics.sh --describe --topic topicName --bootstrap-server broker:9092
list topics
$ bin/kafka-topics.sh --list --bootstrap-server broker:9092
kafka-console-consumer.sh
This regular console consumer doesn’t care about the format of the data; it’ll just print UTF8 encoded bytes. This means you will need to use other consumers in case you are serializing the data using confluent Avro.
Notice that we are using --from-beginning and the --property flags to print the key and consume the events
that are stored in the topic.
$ bin/kafka-console-consumer.sh \
--topic topicName \
--bootstrap-server broker:9092 \
--from-beginning \
--property print.key=true \
--property key.separator="-"
key1-value
key2-value
key3-value
kafka-avro-console-consumer.sh
You’ll use this command to read events serialized in Confluent Avro. You have to include the Schema Registry URL along with the command.
The Avro consumer expects the schema id in the event payload, getting an Unknown magic byte! error if not specified.
Notice that, in Kafka, we can serialize the key and the value of the event in different ways. In this example, we serialized the key using the common String serializer, and the value is serialized using confluent Avro.
This script is distributed with the Confluent Schema Registry docker images.
$ bin/kafka-avro-console-consumer \
--topic topicName \
--bootstrap-server broker:9092 \
--from-beginning
--property schema.registry.url=http://registry:8081 \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property print.key=true \
--property key.separator="-"
key1-{"key": "key1", value: "value"}
key2-{"key": "key2", value: "value"}
key3-{"key": "key3", value: "value"}
Kafkacat
Kafkacat is the most versatile CLI client, allowing us to consume, produce, and list metadata from/to different topics.
We can consume (-C) the events based on a number of events (-c) or the offset or timestamp (-o). By default, Kafkacat will consume all the events stored on the topic.
# Consuming 10 events
$ kcat -C -b broker:9092 -t topicName -c 10
# Consuming from offset 10
$ kcat -C -b broker:9092 -t topicName -o 10
# Consuming events between 2 timestamp
$ kcat -C -b broker:9092 -t topicName -o s@1568276612443 -o e@1568276617901
We can even format the output (-f) and print different information as part of the output.
$ kcat -C -b localhost:9092 -t topic1 \
-f 'topic: %t, Key: %k, message value: %s, offset: %o, partition: %p timestamp: %T, headers: %h, key length: %K, value length: %S \n'
topic: topic1, Key: key1, message value: {"key": "key1", value: "value"}, offset: 0, partition: 0 timestamp: 1568276612443 , headers: , key length: 3, value length: 32
topic: topic1, Key: key2, message value: {"key": "key2", value: "value"}, offset: 1, partition: 0 timestamp: 1568276612443 , headers: , key length: 3, value length: 32
topic: topic1, Key: key3, message value: {"key": "key3", value: "value"}, offset: 1, partition: 0 timestamp: 1568276612443 , headers: , key length: 3, value length: 32
In order to choose the decoders, we have to use the -s flag
# Decode key as 32-bit signed integer and value as 16-bit
$ kcat -b broker:9092 -t topicName -s key='i$' -s value='hB s'
# Decode key and value as avro
$ kcat -b broker:9092 -t topicName -s avro
We can run the kafkacat docker images in case we are working on a container environment with the following command:
docker run --tty \
--network docker-compose_default \
confluentinc/cp-kafkacat \
kcat -C -b broker:9092 -t topicName -o 10
In case we are working on a Kubernetes cluster, we can deploy a kafkacat image and consume the events by jumping inside the pod
apiVersion: apps/v1
kind: Deployment
metadata:
annotations:
kompose.cmd: kompose convert
kompose.version: 1.22.0 (HEAD)
labels:
io.kompose.service: kafkacat
name: kafkacat
spec:
replicas: 1
selector:
matchLabels:
io.kompose.service: kafkacat
template:
metadata:
labels:
io.kompose.service: kafkacat
spec:
containers:
- command:
- sleep
- "100000"
image: confluentinc/cp-kafkacat:latest
name: kafkacat
resources: {}
restartPolicy: Always
status: {}
Kafka Web UI
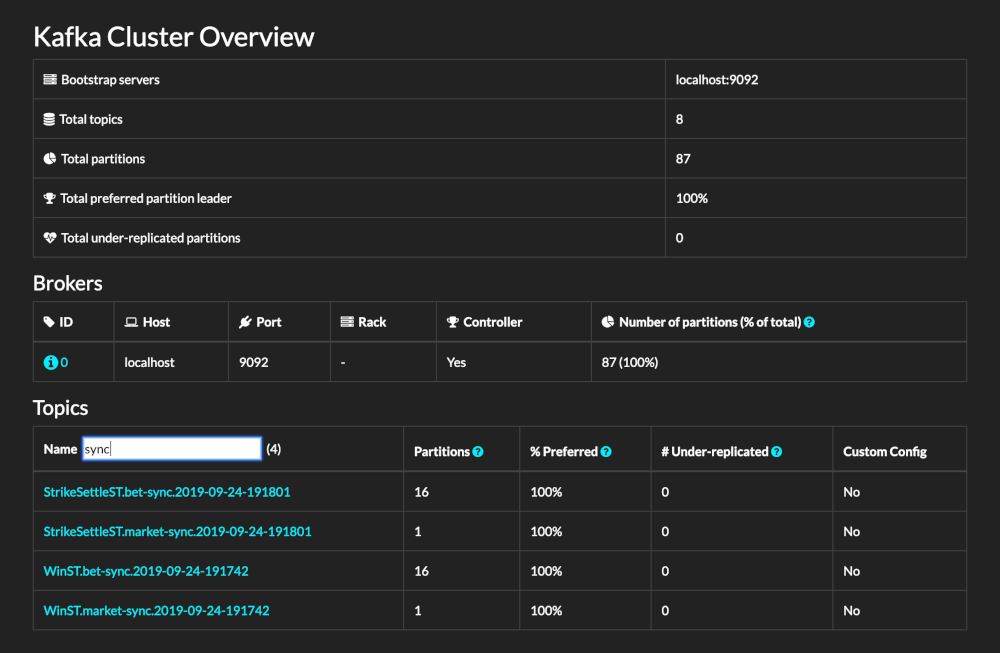
Kafdrop
Kafdrop is an open source web UI for viewing Kafka topics and browsing consumer groups. The tool displays information such as brokers, topics, partitions, and consumers, and lets you view messages. It has support for Docker and Kubernetes, so it is a good option if you are working on container environments.
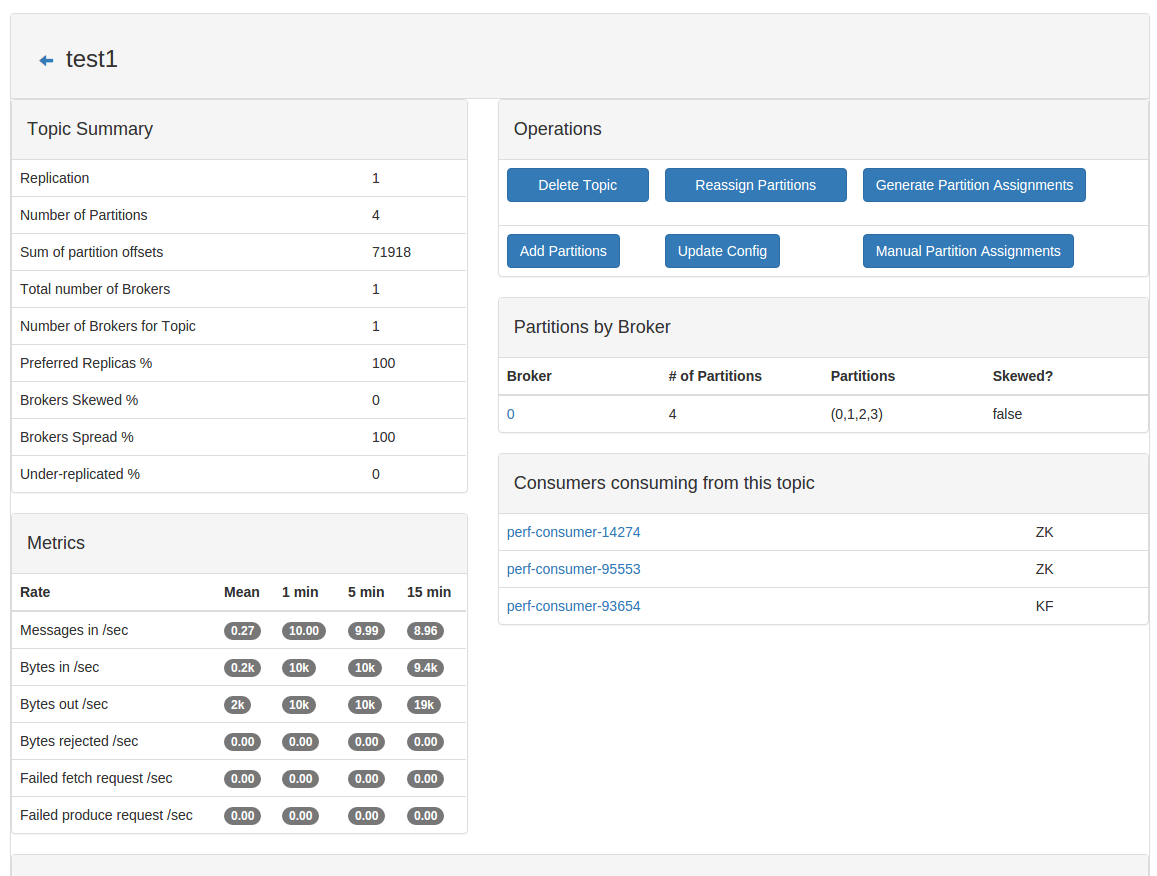
CMAK
CMAK is a cluster manager for Apache Kafka, allowing us to manage multiple clusters and inspect the different topics, messages, and applications that are running inside our cluster and configure the replicas and the partition strategy on the different topics.
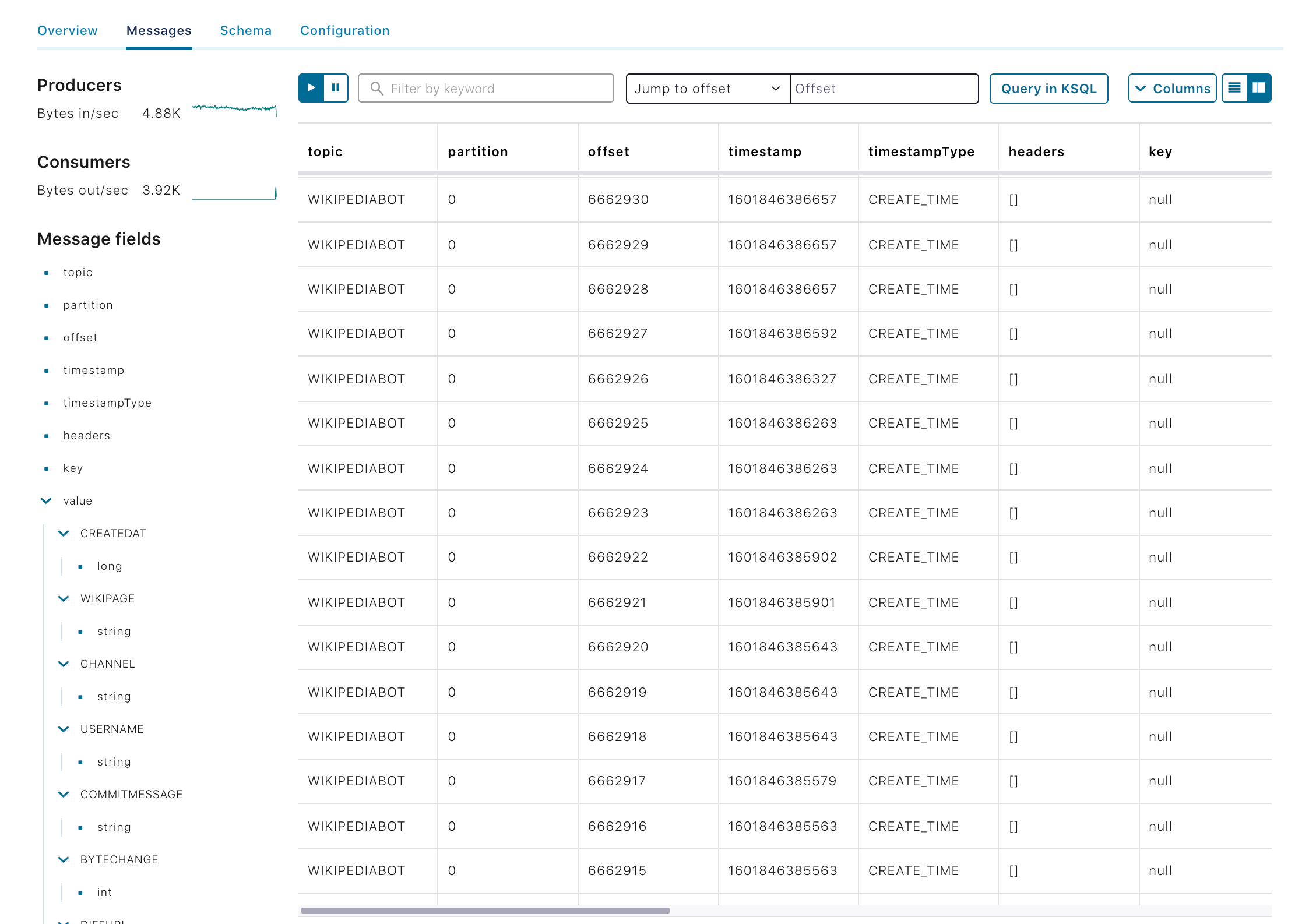
Confluent Control Center
Control Center is another cluster manager for Apache Kafka developed by Confluent. It is similar to CMAK, but includes more features related to Kafka Connectors, alerts, and KsqlDB.
Redpanda Console
Redpanda Console (previously known as Kowl) is a web application that helps you manage and debug your Kafka/Redpanda workloads effortlessly.
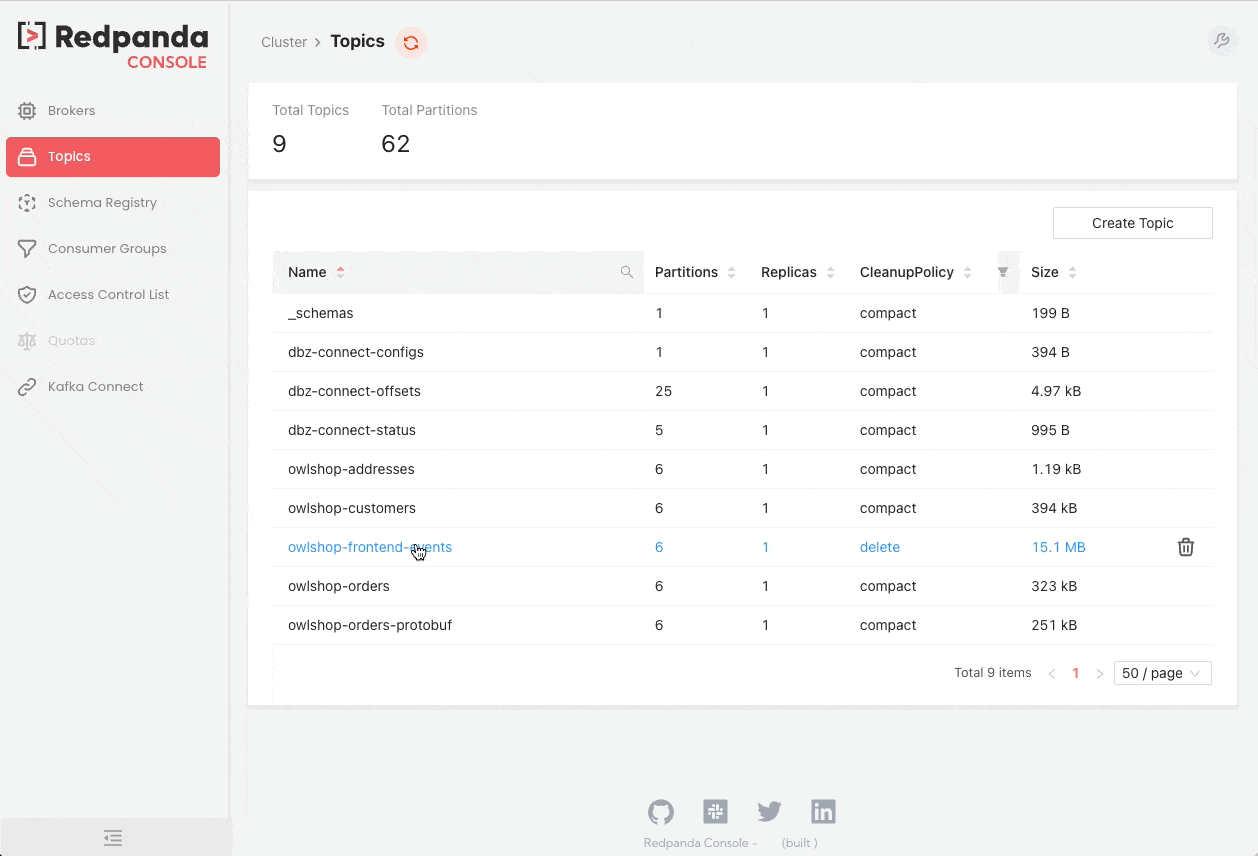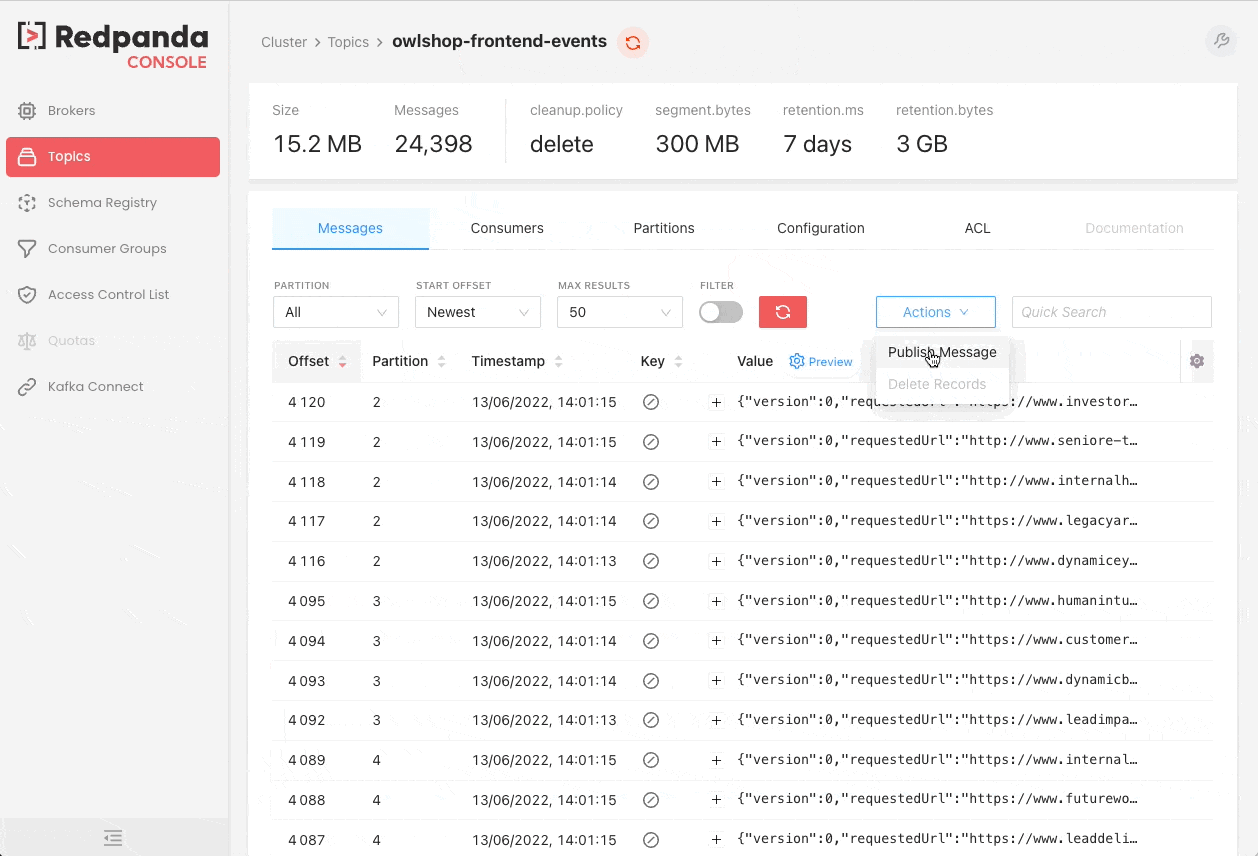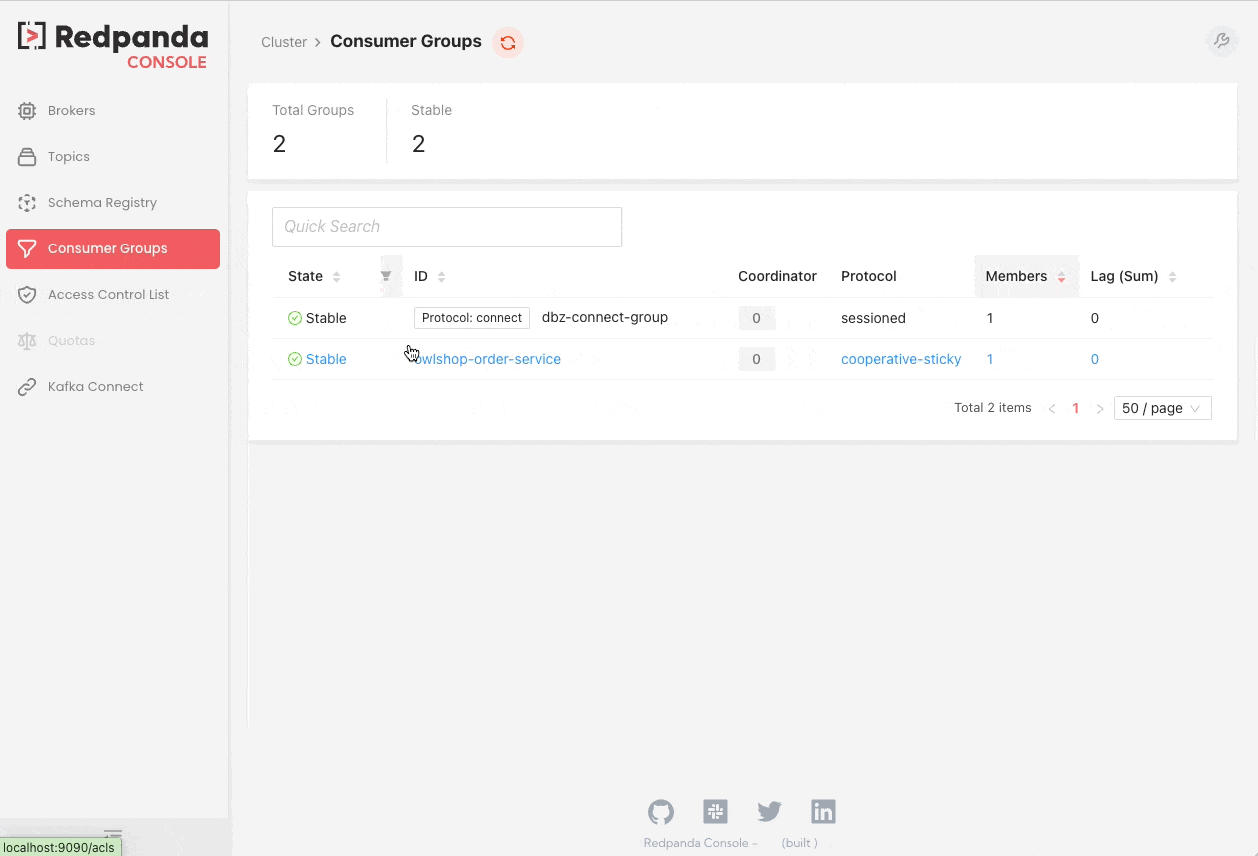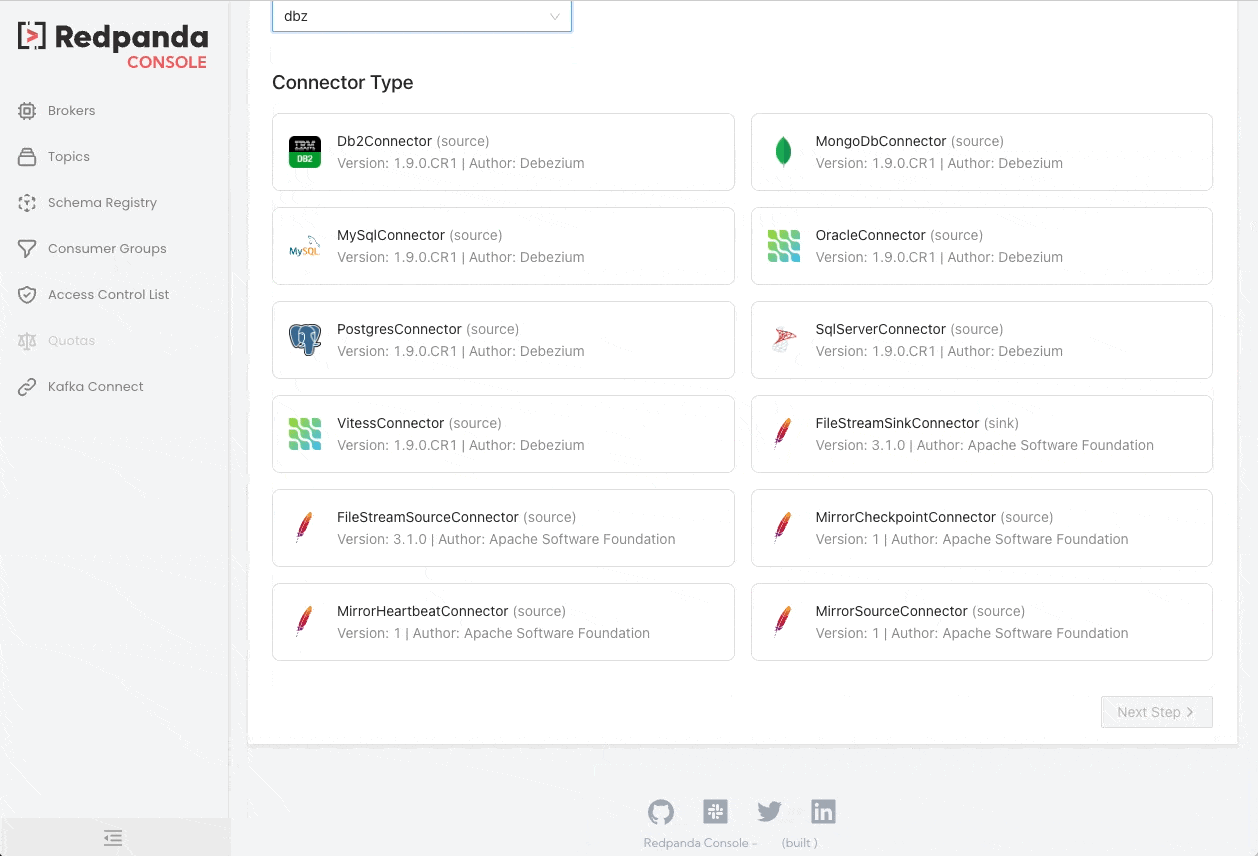
We hope you find these tips and tools helpful in debugging your Kafka projects. Stay tuned for more content on Kafka from the Xebia Functional (formerly 47 Degrees) team!
]]>