Using Fetch for optimizing requests to the GitHub API
 by Alejandro Gomez
by Alejandro Gomez- •
- February 28, 2019
- •
- scala• fetch• scala libraries
- |
- 14 minutes to read.
We’ve just released version 1.0.0 of Fetch, an open source library for simple and efficient data access for Scala and Scala.js. This latest release marks a major overhaul of the library in terms of cats-effect abstractions. It’s backwards-incompatible and introduces numerous breaking changes as well as a couple of new features. It should now be easier to use and require less work from the user, especially if you’re already using cats-effect. You can view the full list of changes in the Fetch v1.0.0 release notes.
We’ll be covering some of the new features and functions and how to utilize them in your projects. To kick things off, we’ll be showing how we use Fetch to optimize requests to GitHub for our open source directory.
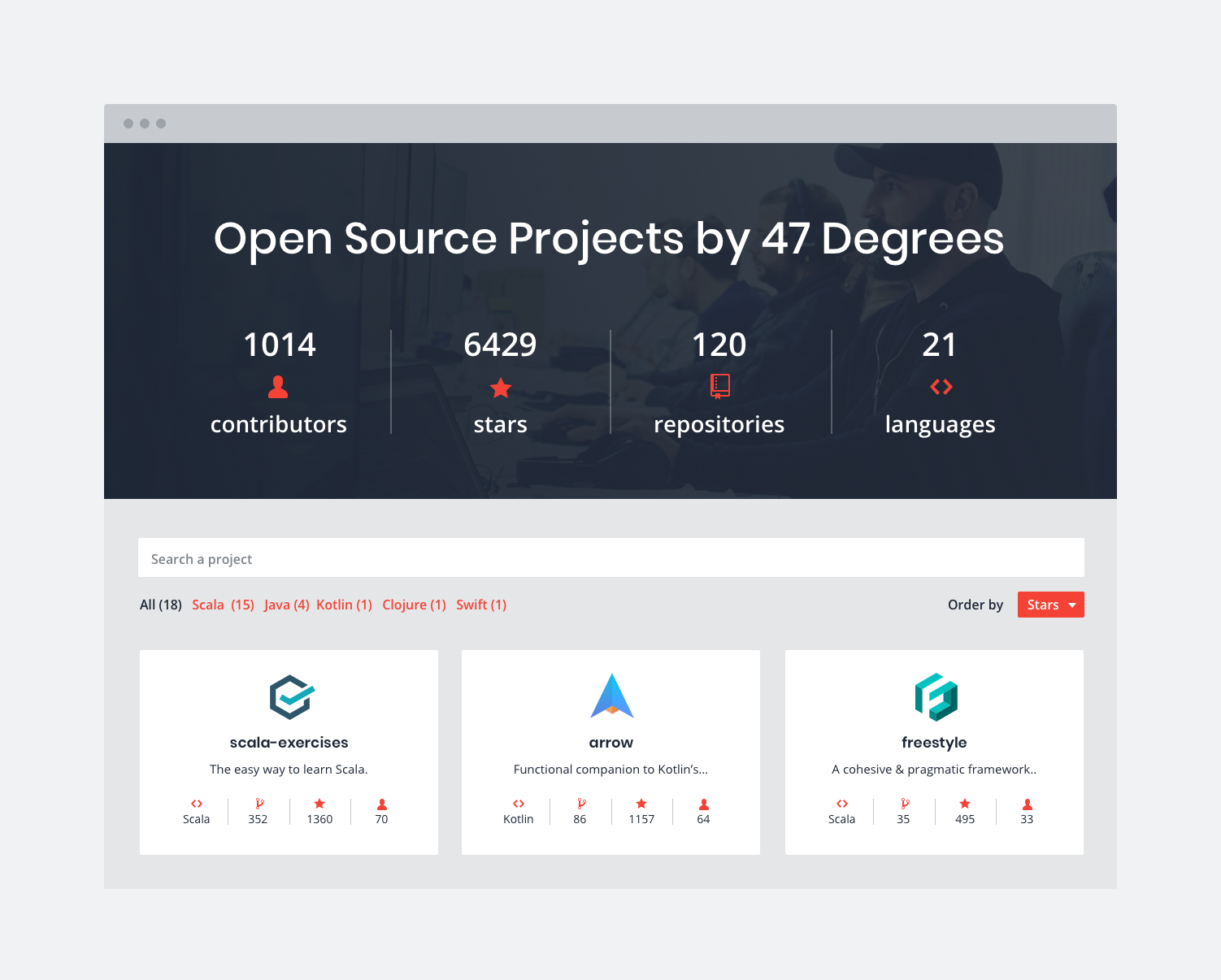
Using Org as an open source directory
We use an open source site to show an overview of the projects that 47 Degrees develops and maintains, as well as some statistics about the organization itself. For each project in the organization, we are interested in:
- What is the primary programming language used in the project?
- How many forks/stars does the project have?
- How many people have contributed to the project?
After we acquire this information, we can compute the total number of stars, repositories, and languages for the organization.

Github API
We start by looking, within Github’s API, for the endpoints they provide for acquiring the information we need. First, we retrieve the list of public repositories of an organization using the Repositories API. As you can see in the following JSON response (abridged), it contains a list of the repositories for the organization:
[
{
"id": 1296269,
"node_id": "MDEwOlJlcG9zaXRvcnkxMjk2MjY5",
"name": "Hello-World",
"full_name": "octocat/Hello-World",
"private": false,
"html_url": "https://github.com/octocat/Hello-World",
"description": "This your first repo!",
"fork": true,
"url": "https://api.github.com/repos/octocat/Hello-World",
"contributors_url": "http://api.github.com/repos/octocat/Hello-World/contributors",
"languages_url": "http://api.github.com/repos/octocat/Hello-World/languages"
}
]
For each of these repos, we would then need to use the languages_url to fetch the corresponding languages, and the contributors_url to fetch its contributors. This means that, for each repository, we need to perform at least two more HTTP requests in order to get the data we want.
Data fetching
Now that we know our data fetching has to perform multiple HTTP requests, it’s tempting to perform a few optimizations by hand to speed up the process. For example, we could fetch all of information from the organization’s repos in parallel, as well as the languages and contributors of each repo simultaneously.
Since we don’t want to pollute our code with such optimizations, we’ll be using Fetch to write our data-fetching code using familiar abstractions like Applicative and Monad. We’ll start with a type for representing repositories, and a function that will return a Fetch for a list of repositories given an organization’s name. We’ll leave the implementation of this type of function out for now:
import fetch._
type Org = String
case class Repo(
name: String,
fork: Boolean,
forks_count: Int,
stargazers_count: Int,
watchers_count: Int,
languages_url: String,
contributors_url: String)
def fetchOrgRepos[F[_] : ConcurrentEffect](org: Org): Fetch[F, List[Repo]] = ???
Since we’ll be adding more information about the project in addition to the basic repository data, we’ll write a Project type that includes information about the repository, languages, and contributors.
case class Contributor(login: String)
type Language = String
case class Project(repo: Repo, contributors: List[Contributor], languages: List[Language])
We’ll also have a function that, given a repository, will return a Fetch for the project.
def fetchProject[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Contributor]] =
(fetchRepoContributors(repo), fetchRepoLanguages(repo)).mapN({
case (contribs, langs) =>
Project(repo = repo, contributors = contribs, languages = langs)
})
def fetchRepoLanguages[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Language]] = ???
def fetchRepoContributors[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Contributor]] = ???
Now that we can fetch all of the required data, we are able to write a function to fetch an organization’s projects. Let’s do it!
def fetchOrg[F[_]: ConcurrentEffect](org: Org): Fetch[F, List[Project]] =
for {
repos <- orgRepos(org)
projects <- repos.traverse(fetchProject[F])
} yield projects
The only missing component is the organization-wide information we show in the page header, which involves computing some project statistics:
def fetchOrgStars[F[_]: ConcurrentEffect](org: String): Fetch[F, Int] =
fetchOrg(org).map(projects => projects.map(_.repo.stargazers_count).sum)
def fetchOrgContributors[F[_]: ConcurrentEffect](org: String): Fetch[F, Int] =
fetchOrg(org).map(projects => projects.map(_.contributors.toSet).fold(Set())(_ ++ _).size)
def fetchOrgLanguages[F[_]: ConcurrentEffect](org: String): Fetch[F, Int] =
fetchOrg(org).map(projects => projects.map(_.languages.toSet).fold(Set())(_ ++ _).size)
We don’t need to worry about fetchOrgStars and the rest using fetchOrg under the hood, since we want our data-fetches to be concise and modular. The library will make sure these get executed efficiently.
We are now equipped to write the function that fetches all the data we need for the website, so let’s give it a go:
def fetch[F[_]: ConcurrentEffect](org: String): Fetch[F, (List[Project], Int, Int, Int)] =
(fetchOrg(org), fetchOrgStars(org), fetchOrgContributors(org), fetchOrgLanguages(org)).tupled
What happens when we execute the above fetch? Let’s take a look at how the library performs the requests to GitHub by using Fetch’s debugging facilities to print the execution log for a Fetch. Be aware that logging adds a bit of overhead that can be avoided by running fetches without recording the execution log.
import fetch.debug.describe
val io = Fetch.runLog[IO](fetch("47deg"))
val (log, result) = io.unsafeRunSync
println(describe(log))
// Fetch execution 🕛 6.70 seconds
// [Round 1] 🕛 3.87 seconds
// [Fetch one] From `Org repositories` with id 47deg 🕛 3.87 seconds
// [Round 2] 🕛 2.71 seconds
// [Batch] From `Languages` with ids List(/* omitted */) 🕛 0.91 seconds
// [Batch] From `Contributors` with ids List(/* omitted */) 🕛 2.71 seconds
Let’s break down the description of the log: Fetch has executed the data fetching in two phases or rounds, the first of which retrieved the repositories for an organization.
Since the language and contributor requests need a project’s information to be performed, Fetch performs another round of execution. This time, it batches all requests for languages and contributors. The Github API doesn’t support batching, so by default, the individual requests run in parallel. For data sources that support batching, Fetch would perform batch requests in one go.
Data sources
We’ve intentionally left out the implementation of the functions for creating fetches since the goal was to show how the library can make fetching data simple and efficient, with little effort. We’ll now have to implement these:
def fetchOrgRepos[F[_] : ConcurrentEffect](org: Org): Fetch[F, List[Repo]] = ???
def fetchRepoLanguages[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Language]] = ???
def fetchRepoContributors[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Contributor]] = ???
We need to implement Fetch’s abstraction for remote data fetching, DataSource, which acts as a recipe for fetching a particular piece of information from a remote source, as well as the function that fetches repositories for an organization:
object Repositories extends Data[Org, List[Repo]] {
def name = "Org repositories"
def source[F[_]: ConcurrentEffect]: DataSource[F, Org, List[Repo]] =
new DataSource[F, Org, List[Repo]] {
def CF = ConcurrentEffect[F]
def data = OrgRepos
def fetch(org: Org): F[Option[List[Repo]]] = {
// ...
}
}
}
def fetchOrgRepos[F[_] : ConcurrentEffect](org: Org): Fetch[F, List[Repo]] =
Fetch(org, Repositories.source)
We create the Repositories object, which we’ll use to identify requests, and a DataSource that, given an organization, fetches a list of repositories. The fetch method of a DataSource needs to be implemented, and you can also implement batch for sources that support batching.
For languages and repositories, the data sources look fairly similar:
object Languages extends Data[Repo, List[Language]] {
def name = "Languages"
def source[F[_]: ConcurrentEffect]: DataSource[F, Repo, List[Language]] =
new DataSource[F, Repo, List[Language]] {
def CF = ConcurrentEffect[F]
def data = Languages
def fetch(repo: Repo): F[Option[List[Language]]] = {
// ...
}
}
}
def fetchRepoLanguages[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Language]] =
Fetch(repo, Languages.source)
object Contributors extends Data[Repo, List[Contributor]] {
def name = "Contributors"
def source[F[_]: ConcurrentEffect]: DataSource[F, Repo, List[Contributor]] =
new DataSource[F, Repo, List[Contributor]] {
def CF = ConcurrentEffect[F]
def data = Contributors
def fetch(repo: Repo): F[Option[List[Contributor]]] = {
// ...
}
}
}
def fetchRepoContributors[F[_] : ConcurrentEffect](repo: Repo): Fetch[F, List[Contributor]] =
Fetch(repo, Contributors.source)
In summary, Fetch allows you to write your data-fetching code in a concise, simple, and elegant way while still executing as efficiently as possible. We simply use combinators from Applicative to express data-independence and Monad to express dependencies between pieces of data without the need for any concurrency constructs.
I intentionally left out the details of performing requests to GitHub since they’re not relevant for this article’s content. If you are interested in the full code for this example, take a look at the GitHub example in the Fetch repository.
The next article in this series will cover how to use Fetch for optimizing GraphQL query execution. In the meantime, feel free to join us at the Fetch Gitter channel to discuss the library or ask questions. As with all of the open source projects under the 47 Degrees umbrella, we’re always looking for new contributors and we’re happy to help guide you towards your first contribution.