Using parsers in practice
 by Alejandro Serrano
by Alejandro Serrano- •
- June 02, 2021
- •
- antlr• parsers• parser combinators• testing• grammarinator
- |
- 13 minutes to read.

For one of our projects, we have created our own small language instead of using an encoding in some serialization format. This language is taken from different languages; Kotlin and Haskell in particular. Developing your own language means writing a parser as a first step. But how do you share the grammar of the language? And, more importantly, how do you test that all the users of the grammar can ingest the same set of programs? This blog post outlines our journey and the lessons we’ve learned in the process.
Deciding for your own language
Before diving into the technical details, it is useful to understand why we wanted to develop our own language in the first place. After all, not reinventing the wheel is usually a good practice, and the world is not devoid of computer languages. For us, the key point is that our language had to support binding, that is, the ability to introduce new names and then refer to those, as we do with arguments in functions.
The subset of languages with serialization support and binding is much smaller. On the one hand, we have extensions of serialization languages, such as JsonLogic. The main problem with those approaches is that they are not very apt for human consumption, and, at the same time, tend to be quite verbose. Here is an example from the JsonLogic documentation:
{"and" : [
{ ">" : [3,1] },
{ "<" : [1,3] }
] }
At the other side of the spectrum, we have the Lisp family, along with their parenthesized expressiveness. Some of them, like Racket, have turned into full language frameworks throughout the years. Alas, choosing any of those languages involves some amount of lock-in into their ecosystem, and we preferred to restrain ourselves to 47 well-known abilities in Kotlin, Scala, and Haskell.
But who can say “no” to parenthetical beauty? S-expressions provide a good balance between maintainability by humans – some humans write these for their entire careers – and ease of production, parsing, and interpretation – since more complex elements in human languages like precedence are not used in Lisp. The expression 3 * 4 + 5 involves some tricks to know whether multiplication or addition “goes first.” The S-expression (+ (* 3 4) 5) has no such problem. That was our final decision: develop our own language, using S-expressions as the base.
Developing the grammar
Once the question about the necessary existence of our language is settled (I might have been listening to Philosophize This too much lately, but it’s sooooo good), it’s time to describe the language and generate the corresponding parser. One of the best known tools in this arena is ANTLR, which is, in principle, geared towards JVM languages, but which has gained support from many other languages over the years. We tried again to avoid lock-in, which ruled out some more powerful alternatives like JetBrains MPS, even though some members of the team are very knowledgeable about this technology since they are the developers of Arrow Meta.
ANTLR follows the traditional approach of dividing the grammar in two parts: the lexer (or tokenizer), and the parser. The former takes care of detecting what is a keyword, what is a number, what is a variable; whereas the latter describes how those elements (known as tokens) combine. In human grammar terms, the lexer recognizes the words, the parser recognizes the sentences. As a consequence, the lexer never “doubts” – if is a keyword, not a variable name – whereas a parser may try several combinations before giving up.
Here is the lexer part of a small grammar – in ANTLR we use ALL_CAPITALS for those. First of all, we describe how comments look in our language, and tell ANTLR to skip that part. We then define a few keywords. Finally, we describe what a symbol looks like using a regular expression: one letter or underscore followed by zero or more letters from SYM_CHAR.
grammar Thingy;
LINE_COMMENT : '//' ~[\r\n]* -> skip;
THEN : 'then' ;
ELSE : 'else' ;
IF : 'if' ;
ADD : '+' ;
MULTIPLY : '*' ;
SYMBOL : INITIAL_SYM_CHAR SYM_CHAR* ;
fragment INITIAL_SYM_CHAR : [a-zA-Z_] ;
fragment SYM_CHAR : [a-zA-Z0-9_.%#$'] ;
Once we have the words, we can describe the sentences. This small language features conditionals, additions, or multiplications of a sequence of expressions – for which we introduce an auxiliary rule op –, function application by simply listing function and arguments, and finally simple symbols. Note that we do not have to worry about ( if x ) being incorrectly parsed as an application since if is always tokenized as an IF symbol and not as a SYMBOL.
op : ADD | MULTIPLY ;
exp : '(' IF exp THEN exp ELSE exp ')'
| '(' op exp+ ')'
| '(' exp+ ')'
| SYMBOL ;
The ANTLR groove
As mentioned above, JVM languages are one of our targets for parsing. Gradle ships with a plug-in, which makes it extremely easy to integrate ANTLR in our workflow. There are a lot of options, and my top suggestion is to generate a visitor instead of a listener if you are used to an FP approach to code.
sourceSets.main.antlr.srcDirs = [file("${ROOT_DIR}/grammar/").absolutePath]
generateGrammarSource {
maxHeapSize = "64m"
arguments += ['-long-messages', '-package', 'com.fortysevendeg.thingy', '-visitor', '-no-listener']
outputDirectory = file("${projectDir}/src/main/java/com/fortysevendeg/thingy/ast")
}
And that’s all! You now have a full-fledged parser that you can use from Java, Kotlin, or Scala.
Checking on the way
One usual problem when developing new languages is how much boilerplate is required for simply testing a few examples. If we went the Kotlin route, we need to rebuild the project, and then set up some way to call the parser. But even in that case, figuring out why some example does not parse could be really challenging. Fortunately, there is an awesome plug-in for Visual Studio Code, which I cannot recommend enough.
Apart from the usual syntax highlighting and navigation, the crown jewel of that plug-in is the ability to debug the parsing process. To do so, you need to create a launch configuration in .vscode/launch.json. The simplest one looks as follows, where you need to change the path to the grammar file and the rule that you want to apply.
{
"version": "2.0.0",
"configurations": [
{
"name": "Debug ANTLR4 grammar",
"type": "antlr-debug",
"request": "launch",
"input": "${file}",
"grammar": "Thingy.g4", // <-- your file
"startRule": "exp", // <-- your "main" rule
"printParseTree": true,
"visualParseTree": true
}
]
}
Now open a new file and write something in your new language. In the Run tab, choose Debug ANTLR grammar, and surprise! A parse tree appears in a new tab. In this case, we are parsing (if something then (+ x y) else who_knows).
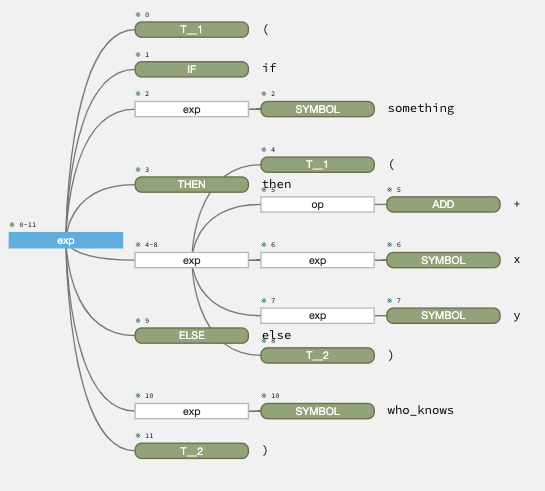
If we now change it to (if something), the parse tree shows where the problem lies: we found IF and a symbol, but then the rule did not expect the closing parenthesis.
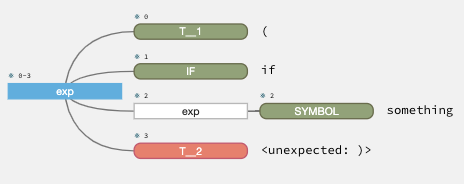
Honestly, the ANTLR plug-in has made our lives so much easier. Even though parsing is only the first step when dealing with a custom language, it usually comes with a lot of pain because the process when using a generator tends to be hard to inspect. Here we have only scratched the surface of the graphical viewer. You can even step throughout the rules and see when it fails; something especially useful when your grammar has lots of ambiguities.
Haskell plays by its own rules
The next step is clear, right? We just need to generate Haskell code from our ANTLR grammar, in the same way that we did with Java, and call it a day. Not so simple, though: the corresponding project requires that we annotate the rule with the Haskell actions, but, by doing so, we break the ability to consume the grammar in Java. After some fiddling, we decided this was a dead end, and went back to our old friend parser combinators.
This is a story that has been told several times, so there’s no need to repeat it here (although, to be fair, most tutorials focus on the implementation, and not so much on the usage). We create our data type to represent the parsed trees.
data Op = Add | Multiply
data Exp = If Exp Exp Exp
| Op Op [Exp]
| App [Exp]
| Var String
And then we use a library like megaparsec and applicative-style to describe the concrete syntax of the grammar. If you want to know more, you can check our Academy courses.
opP :: Parser Op
opP = Add <$ reserved "+" <|> Multiply <$ reserved "*"
expP :: Parser Exp
expP = parens go <|> varP
where varP = ... -- variable parser
go = If <$ reserved "if" <*> expP
<*> reserved "then" <*> expP
<*> reserved "else" <*> expP
<|> Op <$> opP <*> many expP
<|> App <$> many expP
Fortunately, creating a wrapper to run this grammar is an easy task. Just use the parse and give it the string you want to parse.
Do we all agree?
The solution, needless to say, is far from perfect. Whereas our goal was to have a single source of truth – the ANTLR file – we now have two description of the same language, using different technologies. In fact, how do we even know they actually encode the same language? The solution comes again from the ANTLR side, by using a tool called Grammarinator.
Grammarinator works by inverting the parser: instead of taking a string as input, it produces a string as output. This tool works in two phases: first you need to process the grammar. This generates a few files, including ThingyUnlexer and ThingyUnparser.
grammarinator-process Thingy.g4 -o test/generator
And then you can use those generated files to product a lot of strings that satisfy the desired rule, exp in this case. You can customize how big those strings are by changing the -depth and the -number of values to obtain.
grammarinator-generate \
-p test/generator/ThingyUnparser.py \
-l test/generator/ThingyUnlexer.py \
-t Tools.simple_space_serializer \
-r exp \
-o test/generated/test_%d.thingy -d 10 -n 100
The final trick is to then call both the JVM-based and the Haskell-based parsers. Both should accept the strings coming from Grammarinator. Well, that’s the theory. In practice, we had some problems because the random generator was sometimes generating things that ought to be variables but ended up colliding with keywords (like if). The solution was to customize the lexer to always produce symbols with a final number.
class CustomThingyUnlexer(ThingyUnlexer):
def SYMBOL(self):
current = self.create_node(UnlexerRule(name='SYMBOL'))
current += self.unlexer.INITIAL_SYM_CHAR()
current += self.unlexer.DECIMAL()
return current
This works around the corner case. Having Grammarinator as part of our test suite and CI pipeline has saved us from having two parsers drifting apart from each other.
Conclusion
Taking the step of developing your own language can be frightening. Fortunately, with the proper tool support, this can turn out to be as easy as any other part of your system. ANTLR in particular has a big ecosystem around it, which we have leveraged in our project, making it easier to share information between a variety of languages. In fact, at the beginning, adding an additional language (ANTLR) to our already big population of languages didn’t seem like the best idea. But it was clearly one of the best choices we’ve made at the initial phase of our project.
We are 47 Degrees, a Functional Programming consultancy with a focus on the Scala, Kotlin, and Haskell programming languages.